


This page will be updated as and when the rankings change – last update 28th July 2024:

While the best generative AI models are close to each other in quality, there are methods to rank them. The LLM Beefer Upper app has a strict ‘glory hunter’ policy meaning no favouritism: whatever the best model is, it will shamelessly switch to it. Right now the no.1 spot goes to Claude Sonnet 3.5 by a notable margin. I have no doubt that Open AI have something up their sleeves and am ready to be blown away by GPT5 if and when it comes out. But the way things are now, most likely the next best model for 2024 will be Claude Opus 3.5…
Ranking the best generative AI models
For a long time, the most popular ranking site was the LMSYS Chat Arena Leaderboard. The idea makes perfect sense – 1v1 ‘battles’ where human users pick their favourite response and then apply Elo rankings like in Chess. The main problems with it are:
- What humans ‘like’ isn’t necessarily what the most intelligent or valuable output is
- Because people use it for fun rather than for everyday tasks, it biases towards shorter context / no knowledge base / entertaining queries.
- Some people have their favourites and can deliberately select their favoured model based on their linguistic calling cards
- Open AI and Google have been suspected to game the system to increase their rankings on this leaderboard because it’s so popular. This includes experimenting with better quality models than the public get and testing in order to rank higher – as Goodhart's law states: "When a measure becomes a target, it ceases to be a good measure". The fact that recently GPT-4o Mini – a low intelligence (but incredibly cheap) LLM recently shot to a top 3 position illustrates the problem. Nobody would use it for advanced reasoning, creativity or tasks where quality and accuracy are paramount, it’s designed for bulk simple tasks (still awesome for that purpose, but no way should it be threatening the top 5.
Scientifically designed, curated and uncontaminated benchmarking
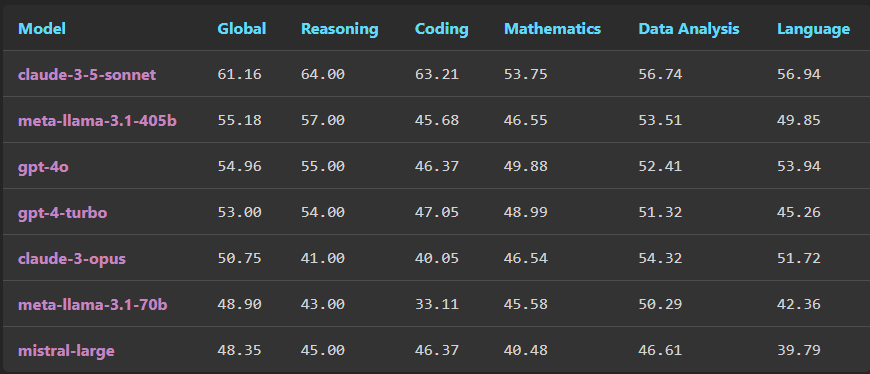
As of now, the most reliable ‘leaderboard’ out there is LiveBench. Set up by experts in the field including NYU, Meta and Nvidia, ensuring no contamination (many popular LLM benchmark questions are in the training data which is disastrous for measuring capabilities), they measure across language, reasoning, coding, maths and data analysis, and here Claude Sonnet 3.5 is a clear winner in every category:
In addition, a recent video by AI Youtuber AI Explained (by far the best ‘AI influencer’ in my view – always measured, no hype, focused on the science and never making claims that aren’t backed up) reveals the results of his own private benchmark. His approach is to design questions that demonstrate human like reasoning intelligence – things that most humans can do but which LLMs currently struggle with (due to their reasoning being dominated by language which is only part of what human intelligence is all about). His results are:
- Humans: 96%
- Claude Sonnet 3.5: 32%
- Meta Llama 405b: 18%
- Open AI GPT4 Turbo: 12%
- Google Gemini 1.5: 11%
- GPT-4o: 5%
As surprising as this may look to those who rely on LMSYS, it looks very much in line with my own experience and that of other heavy LLM users. Claude is usually (not always) better at most tasks. Hats off to Meta for their incredible Llama 405b release recently, they were out of the picture for some time and now the competition for the top is seriously fierce!
***
Connect with me on Linkedin and follow me on Twitter.