


The best LLMs like GPT4 and Claude Sonnet 3.5 are actually better than most people think!

The concept of 'chain of thought' is the most important in AI 'prompt engineering' (apologies for the cringe-inducing terminology, but the fact is how prompts are crafted is massively important and this is currently still the accepted term...) as it stands today. Incorporating stages of critique, reflection, and improvement significantly boosts the quality of LLM outputs. This technique isn't hard to grasp, yet it comfortably outperforms most supposedly 'clever' strategies - I've seen examples of 'quantum entanglement prompting' which are fun to play around with but rarely practical!
The Power of Chain-of-Thought Prompting
Chain-of-Thought (CoT) encourages LLMs to break down complex problems into smaller, more manageable steps, akin to asking a student to "show their work" rather than simply providing a final answer.
The value of CoT prompting can be attributed to its ability to induce a more structured cognitive process within the LLM's neural architecture, facilitating improved information retrieval and logical reasoning. By guiding the AI through a step-by-step reasoning process, we're tapping into the model's full potential, mimicking human problem-solving strategies and leading to more accurate and reliable outputs.
Consider this example:
Basic prompt: “Please generate a clear and comprehensive FAQ from the documentation provided.”
CoT prompts, with 3 subsequent agents each ‘dedicated’ to a particular task:
Agent 1: “Please generate a clear and comprehensive FAQ from the documentation provided.”
Agent 2: “You are an expert in fact-checking and content verification, solely focused on ensuring accuracy. Your task is to thoroughly review the FAQ generated by the first agent, verifying its accuracy and alignment with the source material and initial prompt… <continued>”
Agent 3: “You are an expert reviewer specialised in content optimisation and user experience. Your task is to provide detailed suggestions for improving the FAQ based on the initial draft, the accuracy evaluation, and the original prompt and source material… <continued>”
Agent 4: “You are a master communicator and content creator. Your task is to produce the final version of the FAQ, incorporating all previous feedback and suggestions to create an outstanding resource for the target audience… <continued>”
The chart below is from the Oct 2023 paper Reflexion: An Autonomous Agent with Dynamic Memory and Self-Reflection which illustrates that LLMs can be improved if you give them the opportunity to 'think before they speak':
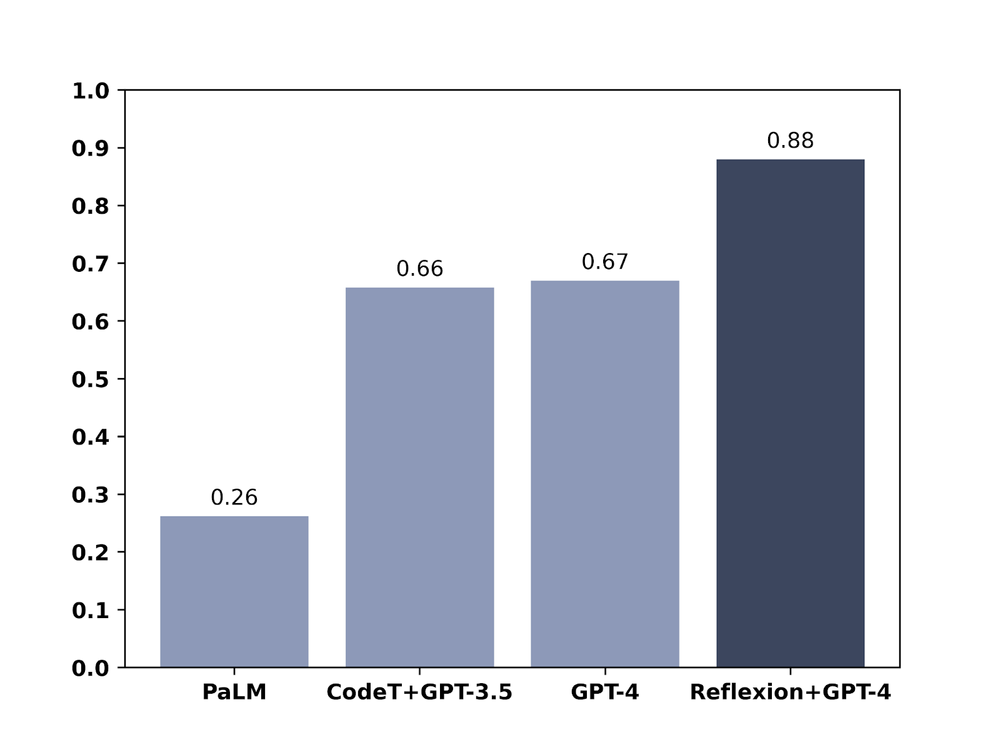
A proven winning technique
The comprehensive 2024 study by Vatsal and Dubey demonstrates that CoT is not limited to a single domain. Their analysis of 39 prompting methods across 29 NLP tasks provides robust evidence for the superiority of chain-of-thought prompting over all other strategies, and by a clear margin. Their findings indicate that CoT consistently outperforms basic prompting, with improvements ranging from 5% to 39% depending on the task complexity. For instance, in tasks requiring mathematical reasoning, CoT demonstrated up to a 39% improvement over basic prompting methods. This substantial performance gain underscores the technique's potential to revolutionise AI interactions across various domains.
Why Your First AI Response doesn’t represent the LLM’s true capabilities
A key phenomenon newcomers to generative AI often overlook is that the first response from an LLM isn't always its best effort. This phenomenon is analogous to human cognition; if someone asked you a complex question, would your immediate, off-the-cuff answer be your most thoughtful response? Especially when it comes to crafting written work - no human ever gets it perfect first time without a single press of the backspace key!
LLMs, in their basic form, tend to generate their first answer based on their existing predictive model, and that's normally still pretty good, but it can easily be improved. This is where techniques like chain of thought come in. They compel the AI to decelerate its processing, consider the problem from multiple angles, and arrive at a more considered conclusion.
Chain of thought prompting, coupled with iterative critique and reflection, mimics human metacognitive processes. In the academic sphere, it simulates the peer review process of ‘revise and resubmit’. This approach allows LLMs to engage in self-monitoring and error correction, which in turn reduces the likelihood of logical inconsistencies or factual inaccuracies in their outputs.
Simplifying the Process with Multi-Agent Templates
While the benefits of chain-of-thought prompting are clear, implementing these techniques can be onerous, especially for those new to using generative AI tools like Chat GPT, Claude, Copilot or Gemini. The LLM Beefer Upper bridges this gap by automating the process, allowing users to implement effective prompt engineering strategies without extensive technical knowledge, thanks to multi-agent prompt templates. The app also gives you the option to build your own custom multi-agent prompt strategies with Claude 3.5 based on your title and description.
Automating Chain of Thought with LLM Beefer Upper
This app is designed to streamline the implementation of CoT and other advanced prompting techniques that use multiple stages or agents, making it accessible to everybody regardless of their technical expertise. By automating the chain of thought process, users can build their own multi-agent templates effortlessly for common LLM tasks that need the best quality results.
Key features of the app include:
- Intuitive multi-agent template creation for continued re-use and refinement
- Automated implementation of CoT and other advanced prompting techniques
- Built-in critique and refinement stages for improved output quality
The app facilitates the creation of a series of prompts that guide the AI through a step-by-step reasoning process. It's akin to having a team of AI experts collaborating to solve your problem. Users can configure one agent to generate an initial response, another to fact-check and critique it, a third dedicated to providing suggestions on how to improve, and then a final one to refine and polish the final output based on the previous agents’ responses (this is the ‘Steak’ quality which produces the best outputs).
This approach not only enforces accuracy verification but also enables more complex and nuanced interactions with AI. To ease users in, the app offers various pre-built templates, as well as using Claude Sonnet 3.5 to generate your agent prompts based on the title and description you provide when creating your own new custom template.
By understanding and applying these methods, you can unlock the true potential of LLMs, achieving more accurate, reliable, insightful and well-written responses. Ultimately, the LLM Beefer Upper simplifies the process of harnessing these advanced techniques. By embracing chain-of-thought prompting and multi-agent templates, you're not just improving your AI outputs – you're radically improving the way you interact with gen AI for massive productivity boosts.
***
Connect with me on Linkedin and follow me on Twitter.