



"Prompt chaining achieves the highest win times (77 out of 100), considerably outshining stepwise prompt in producing higher-quality summaries" (Sun et al. 2024)
Large language models (LLMs) are objectively amazing, except when they're not. In fact they can sometimes generate total nonsense out of nowhere. Prompting is absolutely critical, but even with the best prompts, the first response from an LLM won't be the best. Enter the concept of refinement - a process that mirrors how humans polish their written work, particularly in the academic world of peer review.
Two popular refinement strategies are Prompt Chaining and Stepwise Prompting. But which is the best prompting technique? A recent study by Sun et al. (2024) tackles this question head-on, using text summarisation as their unit of analysis. Let's review their findings and reflect on what they mean for the future of AI-assisted knowledge work.
Prompt Chaining:
This can simply be thought of as a team with a defined division of labour. Using the example from the paper, there are three separate prompts, each handling a specific task:
- Drafting: The LLM generates an initial summary.
- Critiquing: It then provides feedback on its own work.
- Refining: Finally, it uses that feedback to polish the summary.
Stepwise Prompt:
This is more like giving clear instructions to a single individual to make their life easier. A single prompt guides the LLM through all three stages in one go. This became popularised in the past year as the 'think step by step approach'. Both approaches aim to mimic how humans refine their work, but they go about it in distinctly different ways. Here's an illustration from the paper:

The Showdown
Sun et al. put these strategies head to head using the InstruSum dataset, which tasks LLMs with summarising articles based on particular requirements. They employed a variety of models, including GPT-3.5, GPT-4, and Mixtral 8x7B.
The researchers found that Prompt Chaining consistently outperformed Stepwise Prompt. Here's the breakdown:
- Overall Quality: Prompt Chaining produced summaries that better adhered to the given requirements.
- Missing Information: Summaries generated through Prompt Chaining were less likely to omit crucial details.
- Irrelevant Information: Both methods performed similarly in avoiding extraneous information.
- Robustness: The superiority of Prompt Chaining held up across different models, proving that its effectiveness isn't a fluke.
- Human Evaluation: When put to the test with human evaluators, Prompt Chaining again came out on top.
So, why does Prompt Chaining come out on top? Here are the theories:
- Focus: By breaking the process into discrete steps, Prompt Chaining allows the LLM to concentrate fully on each task without getting overwhelmed.
- Clear Delineation: The separation between drafting, critiquing, and refining might help the LLM avoid the temptation to "game" the system, as was noticed on occasion with Stepwise Prompting.
- Human-like Process: Prompt Chaining more closely mimics how humans approach refinement, which might lead to more natural and effective results.
Implementing Prompt Chaining in Your Workflow
Now that we've established Prompt Chaining as the top dog, how can you incorporate it into your AI-assisted tasks? Here are some practical tips:
- Start with a Clear Objective: Before you begin, define exactly what you want your LLM to achieve. This clarity will guide your prompts throughout the process.
- Draft Thoughtfully: Your initial prompt should be comprehensive yet focused. Make it the best you can regardless.
- Critique Constructively: When crafting your critique prompt, be specific about what aspects of the draft need evaluation. This might include factual accuracy, tone, structure, or adherence to specific guidelines.
- Refine with Purpose: In your refinement prompt, explicitly instruct the LLM to address the issues raised in the critique. This ensures that the final output incorporates all necessary improvements.
- Iterate as Needed: Don't be afraid to run through the process multiple times for complex tasks. Each iteration can bring you closer to your desired output.
Potential Drawbacks of Prompt Chaining
While Chain of Thought is still the best prompting method out there, it's not without its challenges:
- Time Investment: Running through multiple prompts can be more time-consuming than a single-step process.
- Complexity: Managing multiple prompts requires more thought and planning, which might be overwhelming for newcomers to AI tools.
- Potential for Conflicting Instructions: If not carefully managed, the different stages of Prompt Chaining could lead to contradictory guidance for the LLM.
- Overreliance on Structure: In some cases, the rigid structure of Prompt Chaining might limit the LLM's ability to make creative leaps or connections.
The LLM Beefer Upper: Your Shortcut to Prompt Chaining Mastery
If you're thinking, "This Prompt Chaining idea sounds brilliant, but it also sounds like a ton of work," you're not wrong. That's literally why the LLM Beefer Upper exists! The app automates the Prompt Chaining process, making it straightforward to implement advanced prompting techniques using proven chain-of-thought and reflection templates without needing a PhD in AI.
While this study focused on text summarisation, the implications reach far beyond. As LLMs continue to evolve and permeate various aspects of our digital lives, understanding how to get the best out of them becomes crucial.
The success of Prompt Chaining opens up exciting possibilities:
- Enhanced Creativity: By refining outputs, we might unlock new levels of AI-assisted creative writing.
- Improved Decision Making: In fields like finance or healthcare, more accurate and refined AI outputs could lead to better-informed decisions.
- Educational Tools: Refined AI outputs could function as learning aids, providing students with clearer, more accurate information.
- Content Creation at Scale: For businesses producing large volumes of content, implementing Prompt Chaining could lead to significant quality improvements with minimal additional time investment.
The LLM Beefer-Upper actually takes it one step further than the strategy used by the researchers: our recommended 4-agent 'Steak-Tier' includes one agent fully dedicated solely to recommending improvements, which amplifies the quality by forcing the division of labour so each LLM agent can focus on its own task. Here's an example of one of our prebuilt templates which achieves outstanding language translation outputs:
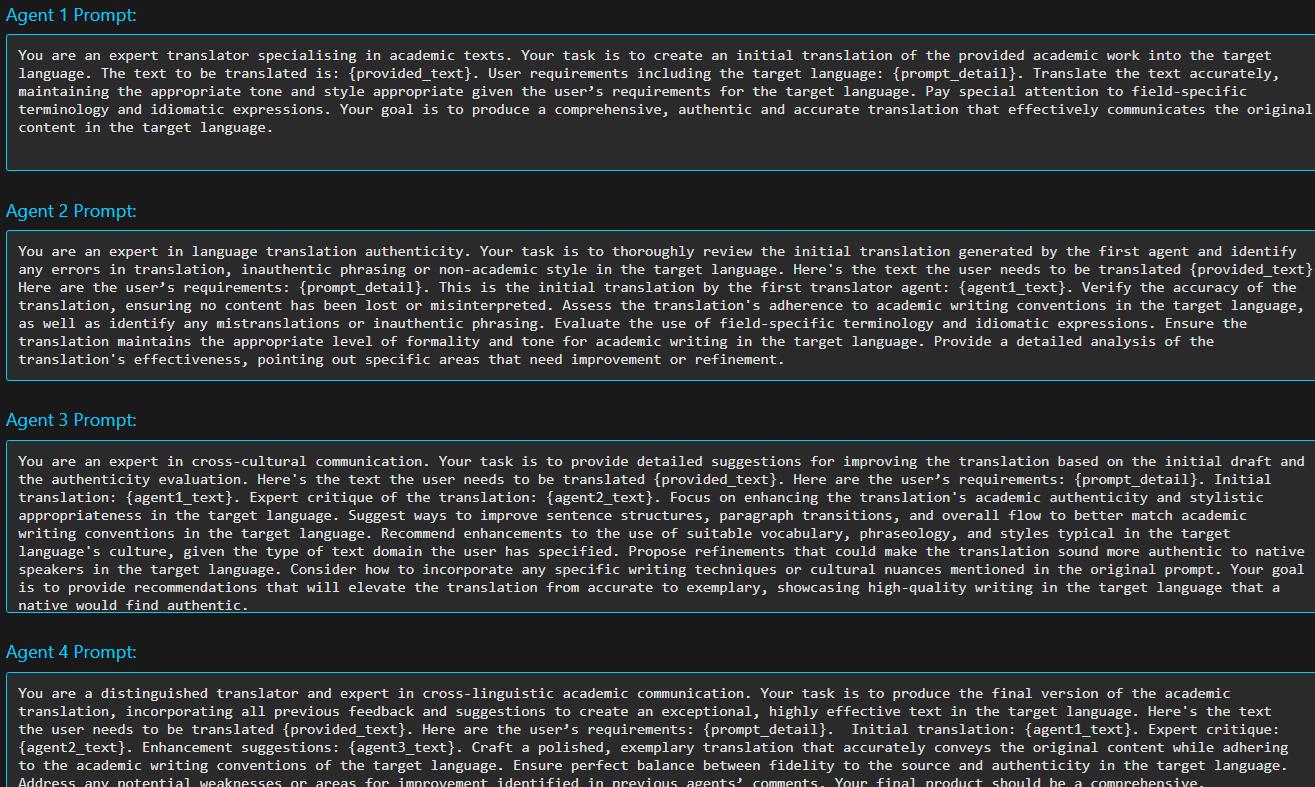
Key Takeaways from the study:
- Prompt Chaining consistently outperforms Stepwise Prompt in generating high-quality, accurate summaries.
- The success of Prompt Chaining likely stems from its focus on discrete tasks and similarity to human refinement processes.
- While powerful, Prompt Chaining does have some drawbacks, including increased complexity and time investment.
The main takeaway is not to settle for the first draft. Feedback from LLM Beefer Upper users shows that 97% agree that the final result was better than the first, so if you want to get the best results from the best prompting technique without putting in a load of effort, give the LLM Beefer Upper a try.